How Black Handles Comments When Python's Grammar Ignores Them
Whenever I started learning about parsing and writing interpreters, I would get to how to handle comments. The gist of it was simple: just throw them out! You find them in the raw text output as you are generating lexing tokens, and discard them, meaning that later phases won't even see them, let alone have to handle them in any real sense.
And this is something that I end up seeing over and over. Just throw out the comments, you don't need them anyways, and almost by definition they can't affect execution.
At this point my understanding is a bit more nuanced, because I have seen stuff like Java document comments, and while it's not the same thing, Python doc strings have some slightly magical properties about them relative to strings in other locations in a file.
But the other day I was looking at Black, and I realized that Black is parsing the Python (duh), but it's also reproducing comments. More than that, it's moving them around and applying logic to them!
The current Python grammar has a lot going on, but appart from a section on type comments (which are more like strings in given positions) there's no place to store comments. And if you put it in the grammar, where does it go? In between every single possible set of tokens?
To figure this out, I decided to take a very small snippet and run it through Black's internal tooling to figure out where all this is going:
def f(x, y):
# add two operands
return (x + y) # yes just this
Inside Black's entry point there's a call to lib2to3_parse. This is actually calling a fork of the venerable lib2to3, powering everyone's favorite 2to3, the thing that kinda sometimes would mostly work for the Python 2 -> 3 transition. Its living on in Black, and serving us well.
This parser returns a bunch of Nodes with some children, or maybe its a Leaf node (holding lexing tokens, presumably). This is our AST!
With some quick graphviz-outputting script, I got the following AST:
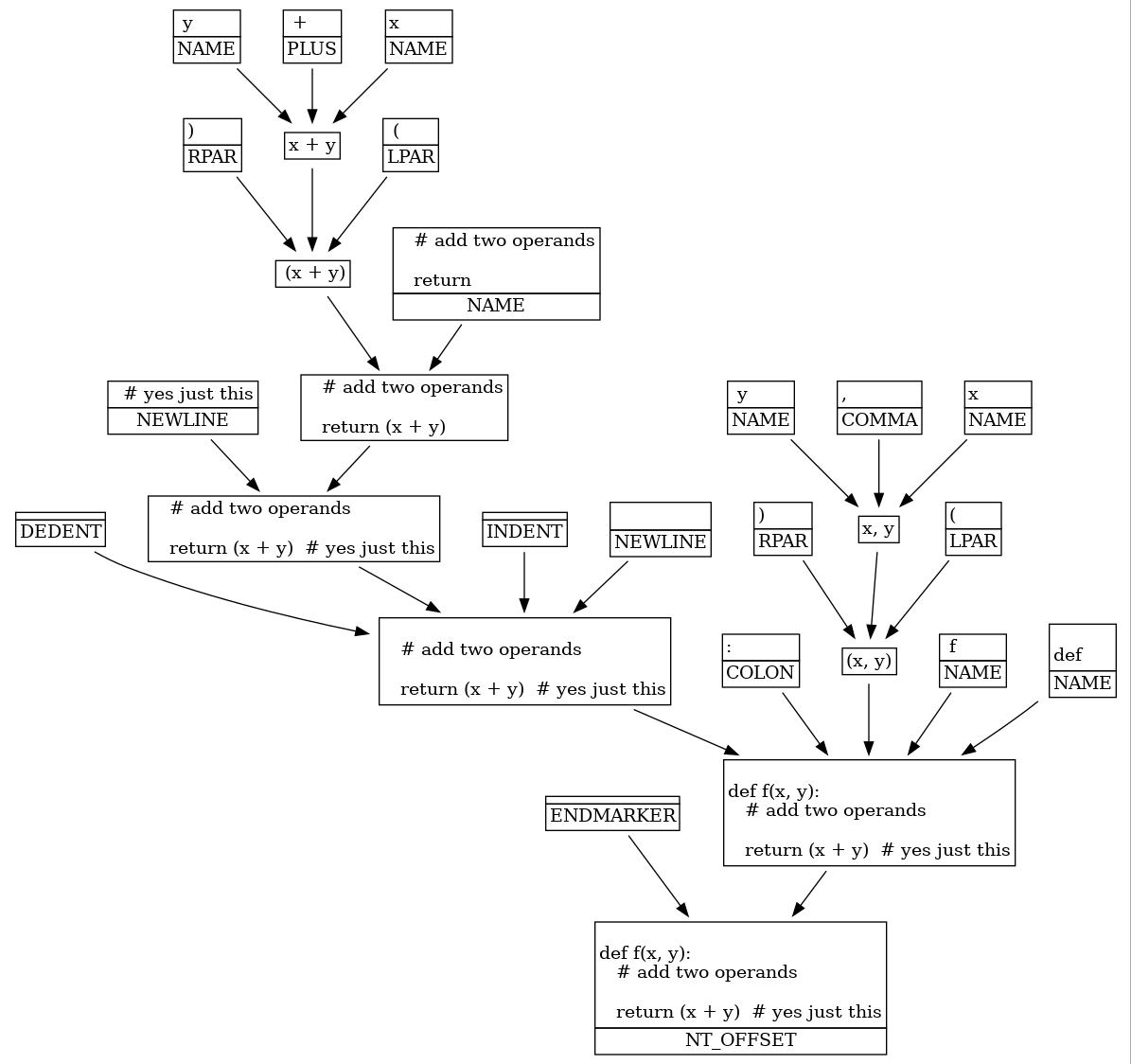
Here Leaf nodes get annotated with a type. You can see, for example, some invisible tokens like ENDMARKER, and INDENT/DEDENT. These are injected at the lexing phase, to end up with simpler parsing. This lets Python's parser look like a C parser, despite not having a bunch of braces all over the place). And there's classic tokens for things like names, commas, parentheses.
I personally find it pretty interesting how even keywords like def end up being represented as a NAME token instead of something more specific. Anyways.
We see some normal stuff like how x + y is composed of x, +, and y. And of course, how return (x+y) breaks down into (x + y) and # add two operands return.
Wait, I'm pretty sure the keyword is just return. And that's not even the comment that's on the line with return!
I broke this down a bit more by diving into the source (barely, the class definitino was enough). Here's a bit more detail in what we're looking at:
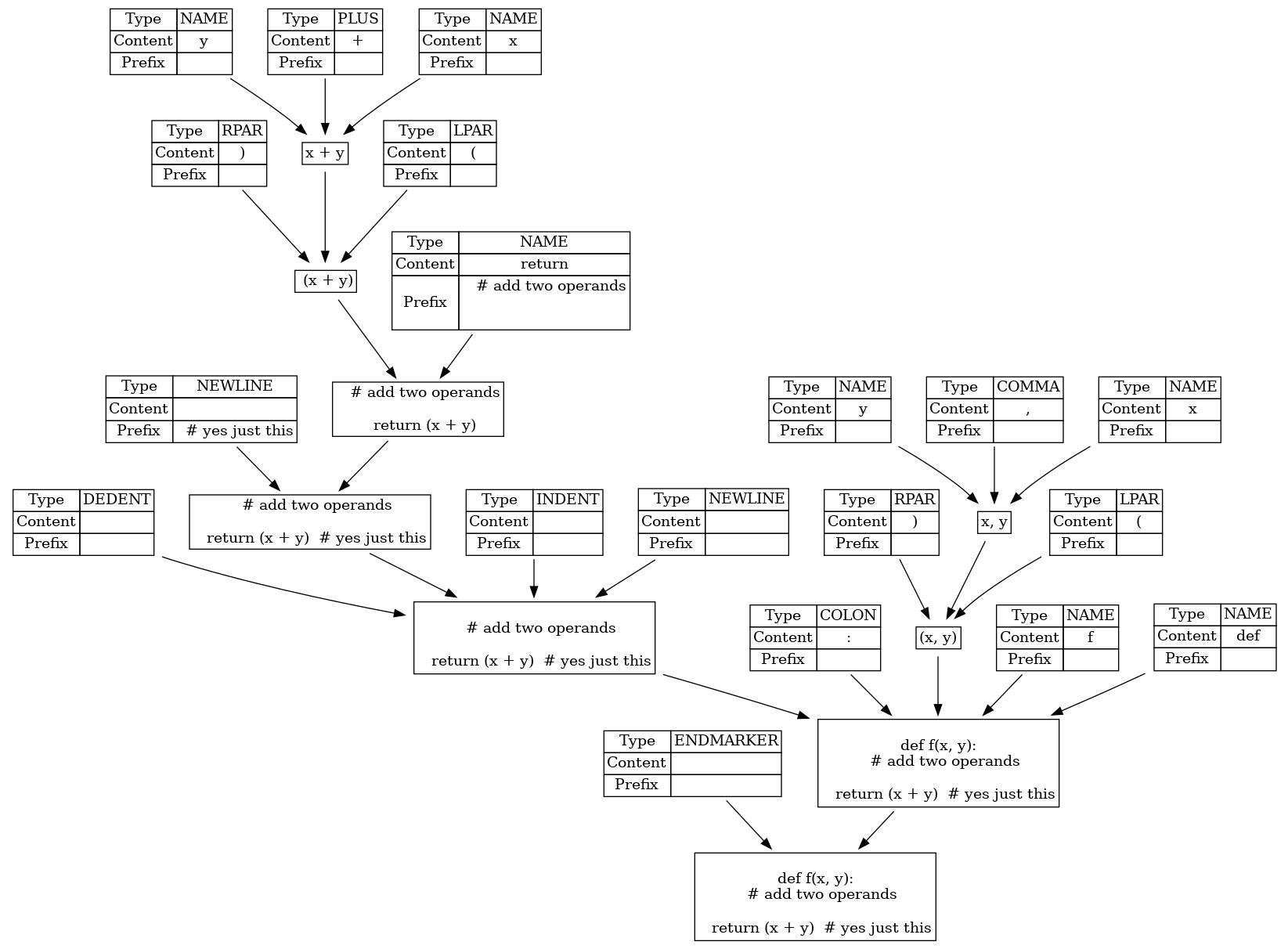
These leaf nodes store their content, to hold the "main" value. But on top of that there's a _prefix parameter that holds all whitespace and comments appearing before this token. In the context of 2to3, I believe that this would allow the code to keep as much of the indentation style as possible when transforming the code, and also to preserve the comments of course.
What does Black do? It follows a simple visitor pattern to traverse the AST, through something called a LineGenerator. For the most part it just keeps on digging until it hits Leaf nodes, as those are where the text is. As it visits these nodes, if it sees that there are comments then it tries to output those first. It (sometimes) will try to shuffle comment stuff around but since Python doesn't have inline comments, it can basically just say "output comments, put in a newline, then keep on outputting the main comment" and that will "just work".
There's also this line post-processor (EmptyLineTracker) that helps with getting output to respect the empty line formatting expectations of the Black style as well. And all of this is so nicely encapsulated that the main code processor ends up being only 30 lines of code, and the innards of the main line generator have some big off-by-1 potential but is otherwise pretty clean!
It's a very nice solution to a problem I'd never really thought of before, and where the "academic" discussion of parsing doesn't really say much.
Behind the scenes
Kate's twitter thread inspired me to try something that involves graphs, and I'd been thinking of Black in general, so I started looking at this.
Graphviz' online documentation looks nicer now. This is the first time I tried out the HTML nodes, and I gotta say, it's nice to just use a thing I know instead of having to spend too much time trying to figure out what magic combo of options gives me a look I like. And as usual, I tried to speedrun through stages of grief up to acceptance when dot would only give me 90% of what I needed for layout.
To be honest though I found out where comments went pretty quickly (I searched for def comments in the codebase and found the generate_comments function with a nice big comment explaining exactly what I was wondering about). This post is basically just laundering that comment. Trying to explain all of this helped deepen my understanding, of course.
Working on this problem is much funner with a good editor. I had Emacs, a script writing to a jpg, that image open with image-mode, and my F9 key bound to running that script. Automatic feedbak, cool drawings and not even needing to alt-tab elsewhere!
Lastly, here is the python script I was using. It's not clean, but it got me what I wanted.